KI-gestützte LinkedIn-Post-Generierung im Test
In der B2B-Kommunikation hat sich LinkedIn als zentrale Plattform etabliert. Besonders für technische Dienstleistungen und Produkte bietet das Netzwerk ideale Möglichkeiten, Fachexpertise zu demonstrieren und qualifizierte Entscheider zu erreichen. Doch die regelmäßige Erstellung hochwertiger Posts, die sowohl fachlich präzise als auch marketing-strategisch effektiv sind, stellt viele Unternehmen vor eine zeitintensive Herausforderung.
Mit der rapiden Entwicklung von Large Language Models (LLMs) eröffnen sich neue Möglichkeiten für die Content-Generierung. Diese KI-Systeme versprechen, basierend auf vorgegebenen Webseiteninhalten und präzisen Anweisungen, zielgruppengerechte LinkedIn-Posts zu erstellen. Doch wie gut funktioniert das in der Praxis? Können LLMs tatsächlich die komplexe Balance zwischen technischer Präzision und Marketing-Appeal treffen?
Die folgende Tabelle zeigt eine Übersicht der Ergebnisse, eine detaillierte Auswertung folgt weiter unten.
| Kriterium (Beschreibung) | GPT-4 | Claude 3.5 | Mistral Le Chat | Gemini | Llama 3.2 | Mistral-nemo | Perplexity | Tibellium |
|---|---|---|---|---|---|---|---|---|
| Prompt-Treue (Einhaltung aller Vorgaben) | 5 | 4 | 5 | 3 | 4 | 4 | 3 | 2 |
| Expertise-Integration (Fachlich & persönlich) | 5 | 5 | 4 | 4 | 3 | 3 | 3 | 3 |
| Sprachqualität (Professionalität) | 5 | 5 | 4 | 4 | 4 | 4 | 4 | 3 |
| Zielgruppen-Relevanz (B2B) | 5 | 5 | 4 | 4 | 4 | 3 | 4 | 3 |
| Content-Struktur (Aufbau) | 5 | 5 | 4 | 5 | 4 | 3 | 2 | 4 |
Bewertungsskala: 5 = Hervorragend, 4 = Sehr gut, 3 = Gut, 2 = Ausreichend, 1 = Mangelhaft
Der Universal-Prompt als Testgrundlage
Die Qualität KI-generierter Inhalte basiert auf präzisen Anweisungen. Für diesen Test entwickelten wir einen umfassenden Prompt, der verschiedene Content-Strategien und Qualitätsanforderungen definiert.
Der Prompt berücksichtigt vier Content-Typen (How-To, Research, Thought Leadership, Case Studies) und integriert meine Rolle als technischer Experte mit Übersetzungshintergrund und künftiger AI-Consultant-Zertifizierung.
Besonderer Fokus lag auf der Integration der Inhalte eines Blogartikels zum EU AI Act auf unserer Webseite und zielgruppengerechten Botschaftsentwicklung.
Formale Vorgaben wie Textlänge, Emoji-Nutzung und Hashtag-Integration sollten LinkedIn-konforme Posts gewährleisten. Die LLMs mussten diese Anforderungen zu einem kohärenten, authentischen Post vereinen.
Acht führende LLMs – von Cloud-Diensten wie GPT-4 bis zu lokalen Open-Source-Modellen wie Llama – erhielten die Aufgabe, einen fachlich fundierten LinkedIn-Post zum EU AI Act zu erstellen. Als Geschäftsführer eines KI-orientierten Übersetzungsdienstleisters interessierte mich besonders die Vermittlung meiner dualen Expertise. Die Ergebnisse zeigen sowohl die Möglichkeiten als auch die Grenzen KI-gestützter Content-Generierung.
Die Online-Modelle: State-of-the-Art KI im Cloud-Zugriff
Für unseren Test haben wir führende Cloud-basierte LLMs ausgewählt, die den aktuellen Stand der KI-Technologie repräsentieren und für jedermann zugänglich sind. Mit GPT-4 von OpenAI, Claude 3.5 Sonnet von Anthropic, Gemini von Google, Mistral Large von Mistral AI und Perplexity mit seinem Sonar-Large-Modell decken wir das Spektrum der leistungsfähigsten verfügbaren Sprachmodelle ab.
Diese Modelle, die auf umfangreichen Serverinfrastrukturen laufen, stellen die Referenz für moderne KI-gestützte Textgenerierung dar. Sie zeichnen sich durch ihre ausgereifte Entwicklung, kontinuierliche Updates und breite Anwendungsmöglichkeiten aus.
Claude 3.5 Sonnet
Entwickler: Anthropic
Veröffentlichung: 22. Oktober 2024
Modelltyp:
- Closed-source
- Teil der Claude 3.5-Modellfamilie
Zugänglichkeit:
- Claude.ai (Web, iOS, Android)
- Anthropic API
- Amazon Bedrock
- Google Cloud Vertex AI
Haupteinsatzgebiete:
- Softwareentwicklung
- Visuelle Datenanalyse
- Fortgeschrittene Chatbots
- Automatisierung komplexer Workflows
Besondere Fähigkeiten:
- Computernutzung (Public Beta)
- Verbesserte Codierungsfähigkeiten
- Erweiterte visuelle Verarbeitung
- 200K Token Kontextfenster
Preismodell:
- $3 pro Million Input-Token
- $15 pro Million Output-Token
- Kostenlose Basisnutzung auf Claude.ai

Strukturelle Analyse
- Länge: Optimal im Zielbereich von 200 Wörtern
- Drei gut strukturierte, dichte Absätze plus Call-to-Action
- Klare thematische Progression
- Professionelles Layout mit guter Lesbarkeit
Inhaltliche Umsetzung
- Content-Typ: Gelungene Kombination aus Data/Research und Thought Leadership
- Starker Hook mit direkter Zielgruppenansprache
- Einbindung konkreter Statistik (73% vs. weniger als 50%)
- Exzellente Verknüpfung von technischer und sprachlicher Expertise
- Fokus auf oft übersehenen Aspekt (Dokumentationspflichten)
Besondere Stärken
- Tiefgehendes Verständnis der Materie
- Einzigartiger Fokus auf technische Dokumentation
- Geschickte Verbindung von Problemstellung und Expertise
- Konkrete Zahlen zur Untermauerung der Argumentation
- Professioneller, aber zugänglicher Schreibstil
Emoji-Nutzung
- 🤔 – Einzelnes, gut platziertes Emoji am Anfang
- Minimalistischer Ansatz (nur 1 statt erlaubter 3-4 Emojis)
- Konservativer, aber professioneller Einsatz
Hashtags
- Präzise, relevante Auswahl
- Gute Mischung aus spezifischen und allgemeinen Tags
- Besonders gut: Einbeziehung von #TechnicalDocumentation als Alleinstellungsmerkmal
Besonderheiten
- Einziger Post, der spezifisch die Dokumentationsanforderungen hervorhebt
- Gelungene Integration der dualen Expertise (Ingenieur und Sprachdienstleister)
- Strategischer Fokus auf oft übersehene Aspekte des AI Acts
- Starke B2B-Positionierung mit klarem Mehrwert
Fazit: Claude 3.5 Sonnet hat einen außergewöhnlich durchdachten Post erstellt, der sich durch einen spezifischen Fokus und tiefgehendes Fachwissen auszeichnet. Die Verknüpfung von technischer Dokumentation mit den AI Act-Anforderungen bietet einen einzigartigen Blickwinkel, der die anderen Posts so nicht aufgegriffen haben. Der einzige kleinere Kritikpunkt ist die sparsame Emoji-Nutzung.
ChatGPT 4o
Entwickler: OpenAI
Veröffentlichung: 13. Mai 2024
Modelltyp:
- Closed-source
- GPT-4-Optimized (GPT-4o)
Zugänglichkeit:
- ChatGPT-Plattform
- API für Entwickler
Haupteinsatzgebiete:
- Multimodale Verarbeitung (Text, Bild, Audio, Video)
- Echtzeit-Konversationen
- Übersetzungen und mehrsprachige Kommunikation
Besondere Fähigkeiten:
- Verbesserte Geschwindigkeit und Effizienz
- Erweiterte multimodale Fähigkeiten
- Emotionserkennung und -wiedergabe
Preismodell:
- Kostenloser Basiszugang (GPT-4o Mini)
- Premium-Zugang über ChatGPT Plus
- API-Preise: 5 USD pro 1 Mio. Input-Tokens, 15 USD pro 1 Mio. Output-Tokens
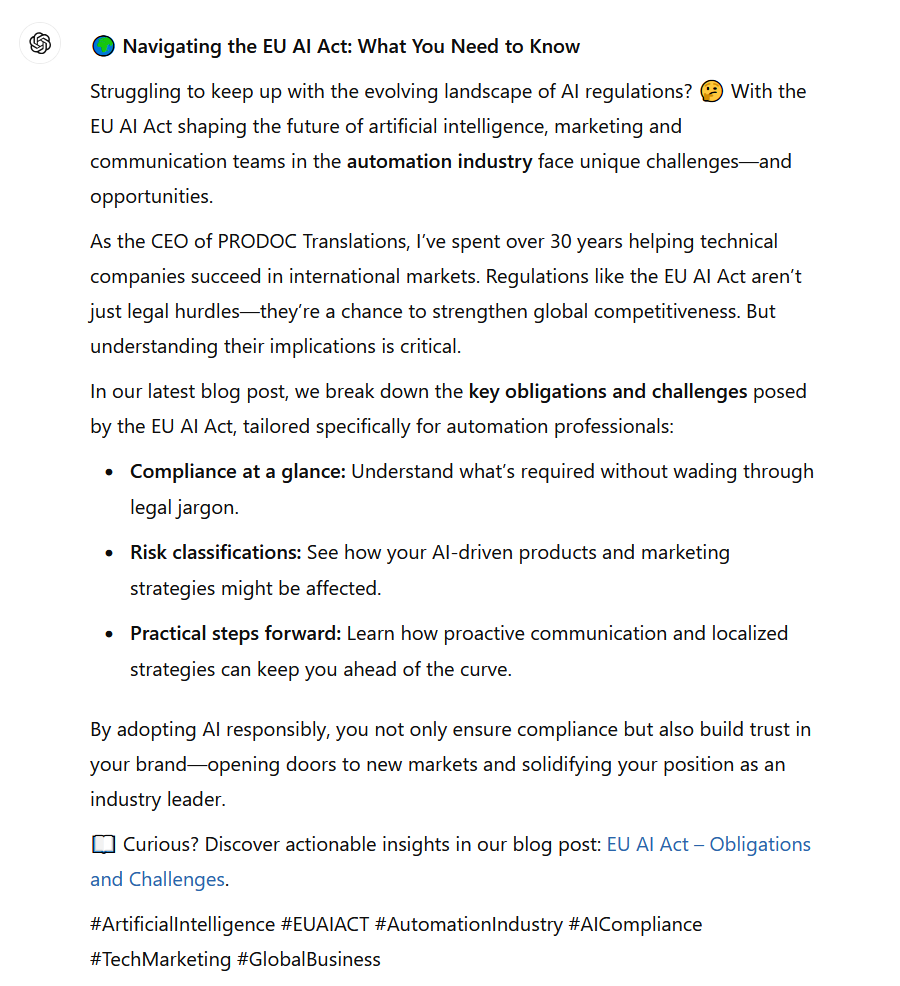
Strukturelle Analyse
- Länge: Optimal im geforderten Bereich (ca. 200 Wörter)
- Klare Gliederung in 5 gut strukturierte Absätze
- Geschickte Integration einer Aufzählungsliste für Kernpunkte
- Professionelles Format mit fettgedruckten Schlüsselbegriffen
Inhaltliche Umsetzung
- Gewählter Content-Typ: Kombiniert Thought Leadership mit How-To-Elementen
- Starker Opening-Hook mit direkter Zielgruppenansprache
- Gelungene Integration meiner Expertise als CEO und langjähriger Branchenexperte
- Klare Werteversprechen und Nutzenargumentation
- Geschickte Verknüpfung von Regulierung und Geschäftschancen
Emoji-Nutzung
- 🌍 – Passend als Opening für globale Regulierung
- 🤔 – Gut platziert bei der Problemstellung
- 📖 – Sinnvoll als Call-to-Action-Marker
- Sparsame und effektive Verwendung (3 Emojis)
Hashtags
- Relevante Auswahl
- Gute Mischung aus spezifischen (#EUAIACT) und breiteren (#GlobalBusiness) Tags
- Angemessene Anzahl (6)
Besondere Stärken
- Professioneller, aber zugänglicher Tonfall
- Ausgezeichnete Balance zwischen Expertise und Approachability
- Klare Strukturierung der Hauptargumente
- Starker Call-to-Action am Ende
Besonderheiten
- Geschickte Verwendung von Fettdruck für Emphasis
- Elegante Überleitung von Problem zu Lösung
- Gelungene Integration meiner Rolle ohne zu werblich zu wirken
Fazit: GPT-4 hat hier einen sehr ausgewogenen, professionellen Post erstellt, der alle Prompt-Anforderungen erfüllt und dabei natürlich und überzeugend wirkt. Besonders hervorzuheben ist die geschickte Verbindung von fachlicher Expertise mit praktischem Nutzen für die Zielgruppe.
Google Gemini 1.5
Entwickler: Google DeepMind
Veröffentlichung: Februar 2024
Modelltyp:
- Closed-source
- Multimodales Large Language Model
Zugänglichkeit:
- Google AI Studio
- Vertex AI
- Gemini API
Haupteinsatzgebiete:
- Textgenerierung und -analyse
- Bildverarbeitung
- Codegenerierung
- Multimodale Aufgaben
Besondere Fähigkeiten:
- 1 Million Token Kontextfenster (erweiterbar auf 2 Millionen)
- Verarbeitung von Text, Bild, Audio und Video
- Verbesserte Leistung bei Übersetzung und Reasoning
Preismodell:
- Kostenlose Testversion
- Kostenpflichtige Nutzung basierend auf Token-Verbrauch
- Google One AI Premium Plan für $19,99/Monat

Strukturelle Analyse:
- Länge: Etwas kürzer als die Zielvorgabe von 200 Wörtern
- Klare Strukturierung mit Fettdruck für Kernaussagen
- Effektive Integration einer Aufzählungsliste
- Übersichtliches Layout
Inhaltliche Umsetzung:
- Content-Typ: How-To mit Thought Leadership-Elementen
- Starker Einstieg mit „What if“-Frage
- Interessante Verknüpfung von AI Act und GDPR
- Klare, strukturierte Darstellung der Hauptpunkte
Besondere Stärken:
- Sehr klare Auflistung der Kernpunkte
- Gute Balance zwischen Regulierung und Geschäftsperspektive
- Professioneller, sachlicher Ton
- Logische Progression der Argumente
Emoji-Nutzung:
- Keine Emojis verwendet (Prompt-Anforderung nicht erfüllt)
- Stattdessen Nutzung von Fettdruck zur Hervorhebung
Hashtags:
- Umfangreiche Hashtag-Liste (10 Tags)
- Gute Mischung aus allgemeinen und spezifischen Tags
- Besonders gut: Einbeziehung von #Translation und #Localization
Schwächen:
- Fehlende Emojis
- Direkte URL statt eleganterer Verlinkung
- Etwas zu kurz
- Könnte persönliche Expertise stärker einbinden
Besonderheiten:
- Einziger Post mit expliziter GDPR-Verbindung
- Stark fokussiert auf regulatorische Aspekte
- Nüchterner, faktenbasierter Ansatz
Fazit: Gemini überzeugt mit einem sehr strukturierten, professionellen Ansatz. Trotz der fehlenden Emojis überzeugt der Post durch klare Organisation und fachliche Tiefe. Die explizite Verbindung zum GDPR bietet einen interessanten zusätzlichen Blickwinkel, den andere Modelle nicht aufgegriffen haben.
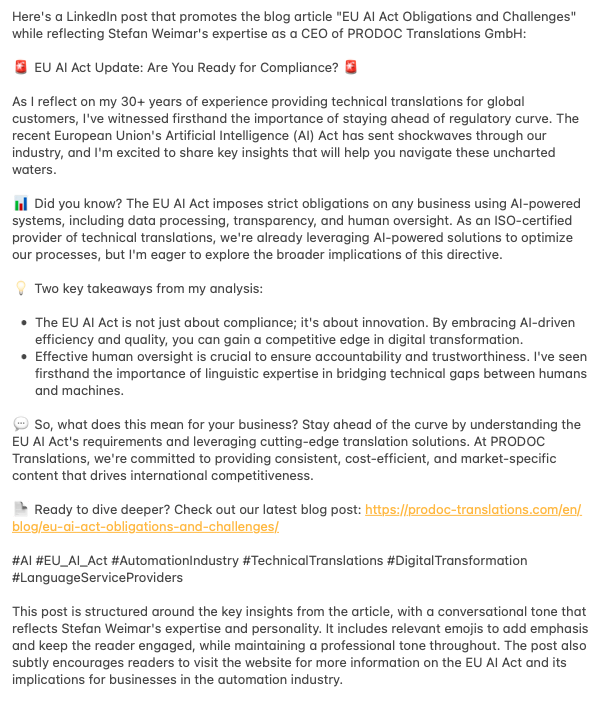
Perplexity.ai mit Sonar Huge
Entwickler: Perplexity AI
Veröffentlichung: Juli 2024
Modelltyp:
- Closed-source
- Basierend auf Meta’s Llama 3.1 405B
Zugänglichkeit:
- Online via API
- Perplexity AI’s LLM-Playground
Haupteinsatzgebiete:
- Komplexe Suchanfragen
- Tiefgreifendes Reasoning
- Echtzeit-Informationsverarbeitung
Besondere Fähigkeiten:
- 128K Token Kontextfenster
- Internetzugriff für aktuelle Informationen
- Erweiterte Suche auf X und Reddit
- Mehrsprachige Unterstützung
Preismodell:
- Premium-Modell (5$ pro 1M Token)
- Teil des Perplexity Pro-Abonnements

Strukturelle Analyse
- Länge: Im Zielbereich von ca. 200 Wörtern
- Klare Absatzstruktur, aber die Formatierung zeigt Schwächen (fehlende Zeilenumbrüche)
- Integration einer Aufzählungsliste mit Bulletpoints
- Auffällig: Fehlende Leerzeichen nach Satzzeichen
Inhaltliche Umsetzung
- Content-Typ: Kombination aus Research/Data Content und Thought Leadership
- Starker Einstieg mit persönlicher Expertise
- Konkrete Zahlen und Fakten (€30 Millionen, 6%, vier Risikolevel)
- Gelungene Integration von Expertenwissen
- Effektive Verwendung rhetorischer Fragen am Ende
Besondere Stärken
- Konkrete, actionable Informationen
- Klare Darstellung der Risiken und Konsequenzen
- Gute Balance zwischen Fachwissen und Zugänglichkeit
- Effektiver Spannungsaufbau durch strategische Fragen
Emoji-Nutzung
- 🤖 – Einzelnes Emoji am Anfang
- Minimalistischer Einsatz (nur 1 statt der erlaubten 3-4 Emojis)
- Passendes Symbol für KI-Thematik, aber mehr emotionale Akzente wären möglich gewesen
Hashtags
- Relevante und themenspezifische Auswahl
- Gute Mischung aus spezifischen und allgemeinen Tags
- Angemessene Anzahl (6)
Schwächen
- Formatierungsprobleme (fehlende Abstände)
- Unterdurchschnittliche Emoji-Nutzung
- Etwas abrupter Übergang zum Call-to-Action
Besonderheiten
- Starker Fokus auf konkrete Zahlen und Fakten
- Effektive Nutzung rhetorischer Fragen
- Gelungene Verbindung von persönlicher Erfahrung und aktueller Entwicklung
Fazit: Perplexity/Sonar Huge hat einen inhaltlich starken Post erstellt, der besonders durch konkrete Fakten und klare Handlungsimplikationen überzeugt. Die technischen Formatierungsschwächen und die sparsame Emoji-Nutzung sind die hauptsächlichen Verbesserungspunkte.
Mistral Le Chat
Entwickler: Mistral AI
Veröffentlichung: Februar 2024, umfangreiches Update im November 2024
Modelltyp:
- Closed-source
- Basiert auf Mistral-Modellen, nutzt Pixtral Large für multimodale Verarbeitung
Zugänglichkeit:
- Kostenlose webbasierte Chatbot-Plattform
- API für Entwickler
Haupteinsatzgebiete:
- Textgenerierung und -analyse
- Bildverarbeitung und -generierung
- Dokumentenanalyse
- Websuche mit Quellenangaben
Besondere Fähigkeiten:
- Multimodale Verarbeitung (Text, Bilder, PDFs)
- Canvas-Tool für kreatives Arbeiten
- Integration von Flux Pro für Bildgenerierung
- Unterstützung für automatisierte Workflows
- 128K Token Kontextfenster
Preismodell:
- Kostenlose Nutzung aller Funktionen (Stand: November 2024)
- Kostenpflichtige Enterprise-Version verfügbar
Special Feature:
Europäisches Modell, wird nur auf Servern in der EU nach EU-Datenschutzrichtlinien gehostet
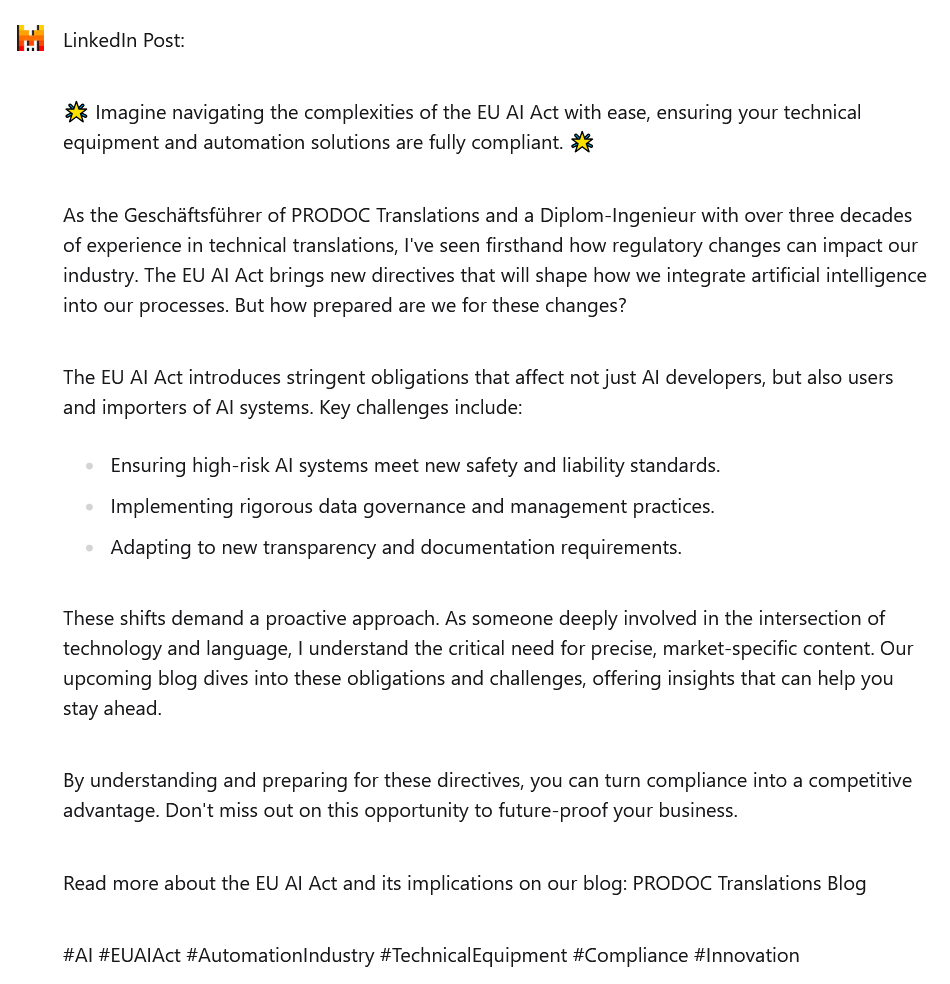
Strukturelle Analyse
- Länge: Gut im Zielbereich von 200 Wörtern
- Klare Absatzstruktur mit logischer Progression
- Effektive Integration einer Aufzählungsliste
- Professionelle Gliederung
Inhaltliche Umsetzung
- Content-Typ: Kombination aus How-To und Thought Leadership
- Starker „Imagine“-Einstieg schafft positive Vision
- Gute Balance zwischen Herausforderungen und Lösungen
- Klare Strukturierung der Hauptpunkte
- Geschickte Integration der persönlichen Expertise
Besondere Stärken
- Positiver, lösungsorientierter Ansatz
- Sehr klare Auflistung der Hauptherausforderungen
- Gelungene Verbindung von Expertise und Praxisrelevanz
- Authentische Integration des deutschen Titels „Geschäftsführer“
Emoji-Nutzung
- 🌟 – Doppelte Verwendung als „Rahmen“ des ersten Satzes
- Minimalistischer, aber effektvoller Einsatz
- Interessante symmetrische Platzierung
Hashtags
- Relevante, gut gewählte Auswahl
- Interessante Einbindung von #TechnicalEquipment
- Angemessene Anzahl (6)
Schwächen
- Etwas generische Call-to-Action Formulierung
- „PRODOC Translations Blog“ als Link-Text statt einer spezifischeren Beschreibung
Besonderheiten
- Einziger Post, der deutsche Begriffe (Geschäftsführer, Diplom-Ingenieur) integriert
- Stark zukunftsorientierter, positiver Ton
- Fokus auf proaktives Handeln
- Gute Balance zwischen Autorität und Zugänglichkeit
Fazit: Mistral Le Chat hat einen sehr ausgewogenen, professionellen Post erstellt, der sich durch seinen positiven, zukunftsorientierten Ton auszeichnet. Die Integration deutscher Titel verleiht dem Post eine besondere Authentizität. Besonders gelungen ist die klare Strukturierung der Herausforderungen bei gleichzeitiger Betonung der Chancen.
Die Open-Source-Alternative: Lokale Modelle auf Standard-Hardware
Bei der Auswahl der lokalen Open-Source-Modelle stand die praktische Nutzbarkeit auf Standard-Hardware im Vordergrund. Alle Tests wurden auf einem MacBook Pro (2021) mit M1-Chip und 32 GB RAM durchgeführt. Wir wählten drei Modelle unterschiedlicher Größe: Das kompakte Llama 3.2 (3B Parameter), das spezialisierte Tower-Instruct-Mistral (7B Parameter) und das Mistral-Nemo (12B Parameter).
Besonders interessant: Das Tower-Instruct-Modell, eigentlich für Übersetzungen optimiert, wurde bewusst für eine fachfremde Aufgabe getestet. Bemerkenswert war die Reaktionsgeschwindigkeit – alle lokalen Modelle erreichten trotz ihrer begrenzten Größe Antwortzeiten auf dem Niveau der Cloud-Dienste. Dies demonstriert eindrucksvoll, wie leistungsfähig moderne KI-Modelle auch auf Standard-Hardware sein können.
Mistral NeMo 12B
Entwickler: Mistral AI und NVIDIA – Download bei Ollama
Veröffentlichung: Juli 2024
Modelltyp:
- Open-source
- Transformer-Architektur
Zugänglichkeit:
- Downloadbare Checkpoints
- NVIDIA NIM Inference-Microservice
- La Plateforme von Mistral AI
Haupteinsatzgebiete:
- Chatbots
- Mehrsprachige Aufgaben
- Programmierung
- Zusammenfassungen
Besondere Fähigkeiten:
- 128k Token Kontextfenster
- Herausragende Leistung bei Reasoning und Coding
- Unterstützung für über 100 Sprachen
- Quantisierungsbewusst trainiert (FP8-Inferenz)
Preismodell:
- Open-source (Apache 2.0 Lizenz)
- Kostenpflichtige Nutzung über Cloud-Dienste möglich

Strukturelle Analyse
- Länge: Etwas kürzer als die geforderten 200 Wörter
- Klare visuelle Strukturierung durch Absätze
- Auffällig: Übermäßige Verwendung von Fettdruck (markiert durch **)
- Gut integrierte Aufzählungsliste
- Deutliche Zeilenumbrüche verbessern die Lesbarkeit
Inhaltliche Umsetzung
- Content-Typ: How-To/Tutorial mit Elementen von Thought Leadership
- Persönlicher Einstieg mit meiner Expertise
- Klare Problemstellung
- Konkrete, actionable Insights in der Aufzählungsliste
- Starker Call-to-Action am Ende
Besondere Stärken
- Sehr persönlicher, direkter Ton
- Gelungene „Problem-Solution“-Struktur
- Klare, actionable Kernpunkte
- Authentische Integration meiner Expertise
Emoji-Nutzung
- 🤔 – Passend für die einleitende Frage
- 🤯 – Verstärkt das „Overwhelmed“-Gefühl
- 💡 – Klassisch für Insights/Lösungen
- 🚀 – Dynamisches Symbol für Call-to-Action
- Gute Verteilung und sinnvolle Platzierung
Hashtags
- Umfangreiche, relevante Auswahl (7 Hashtags)
- Gute Mischung aus allgemeinen und spezifischen Tags
- Sinnvolle Einbeziehung von Branchenspezifika
Schwächen
- Übermäßige Fettdruck-Formatierung
- Etwas zu kurz für die Zielvorgabe
- Titel des Blogposts könnte besser integriert sein
Besonderheiten
- Sehr dialogischer Stil
- Starke Betonung der gemeinsamen Herausforderungen („like you and me“)
- Optimistischer, lösungsorientierter Ansatz
Fazit: Mistral-nemo hat einen dynamischen, persönlichen Post erstellt, der durch seinen direkten Kommunikationsstil und die klare Strukturierung überzeugt. Die technischen Formatierungsprobleme (übermäßiger Fettdruck) und die etwas zu knappe Länge sind die Hauptkritikpunkte. Besonders positiv fällt die authentische Integration meiner Rolle und die klare Zielgruppenansprache auf.
Llama 3.2 3B
Entwickler: Meta AI – Download bei Ollama
Veröffentlichung: September 2024
Modelltyp:
- Open-source
- Llama-Modellfamilie
Zugänglichkeit:
- Download auf llama.com und Hugging Face
- Nutzung über Cloud-Plattformen (AWS, Google Cloud, Microsoft Azure)
- Lokale Ausführung auf Edge-Geräten möglich
Haupteinsatzgebiete:
- Multilingualer Dialog
- Agentenbasierte Informationssuche
- Zusammenfassungen
Besondere Fähigkeiten:
- Übertrifft vergleichbare Modelle bei Aufgaben wie Anweisungsbefolgung und Textzusammenfassung
- Unterstützt 128K Token Kontextlänge
- Optimiert für Edge-Computing und mobile Geräte
Preismodell:
- Kostenlos für viele kommerzielle Anwendungsfälle
Strukturelle Analyse
- Länge: Gut im Zielbereich von 200 Wörtern
- Klare Absatzstruktur mit logischem Aufbau
- Effektive Integration einer Aufzählungsliste
- Professionelles Layout mit guten Zeilenumbrüchen
Inhaltliche Umsetzung
- Content-Typ: Mischung aus Thought Leadership und Practical Insights
- Starker persönlicher Einstieg mit Erfahrungsbezug
- Gelungene Balance zwischen Regulierung und Innovation
- Konkrete Takeaways mit praktischem Nutzen
- Geschickte Integration der Unternehmensexpertise
Besondere Stärken
- Exzellente Verbindung von persönlicher Erfahrung und aktueller Entwicklung
- Klare Herausarbeitung des Mehrwerts
- Gute Balance zwischen Warnung und Chancen
- Starke Integration der dualen Expertise (technisch und sprachlich)
Emoji-Nutzung
- 🚨 – Doppelte Verwendung als Attention-Grabber (etwas überdramatisch)
- 📊 – Passend für Daten/Statistiken
- 💡 – Klassisch für Insights
- 💬 – Gut für den Dialog-Teil
- 📄 – Passend für den Call-to-Action
- Reichliche, aber sinnvolle Verwendung
Hashtags
- Gut gewählte, relevante Tags
- Interessante Verwendung von Unterstrichen (EU_AI_Act)
- Angemessene Anzahl (6)
Schwächen
- Direkte URL-Einbindung (statt subtilerer Verlinkung)
- Leicht überdramatischer Einstieg mit doppeltem Alarm-Emoji
Besonderheiten
- Sehr gelungene Integration der Unternehmenspositionierung
- Geschickte Verknüpfung von AI Act und Übersetzungsexpertise
- Klare Betonung des Wettbewerbsvorteils
Fazit: Auffällig ist, dass Llama 3.2 trotz seiner geringeren Parameterzahl einen sehr professionellen, durchdachten Post erstellt hat. Die zusätzliche Erklärung am Ende zeigt interessanterweise, dass das Modell seine eigenen Entscheidungen reflektieren kann – eine unerwartete Zusatzleistung.
TowerInstruct
Entwicklerdoku: Unbabel – Download bei Ollama
Veröffentlichung: Februar 2024
Modelltyp:
- Open-source
- Basiert auf LLaMA 2
Zugänglichkeit:
- Über Hugging Face
- Lokal ausführbar mit Docker in einer VM oder direkt per Ollama
Haupteinsatzgebiete:
- Maschinelle Übersetzung
- Automatische Nachbearbeitung
- Named-Entity Recognition
- Grammatikkorrektur
- Paraphrasengenerierung
Besondere Fähigkeiten:
- Unterstützt 10 Sprachen
- Hervorragende Leistung bei Übersetzungsaufgaben
- Konkurrenzfähig mit GPT-3.5 und teilweise GPT-4
Preismodell:
- Kostenlos nutzbar (Open-Source)

Strukturelle Analyse
- Länge: Im Zielbereich von etwa 200 Wörtern
- Klare Absatzstruktur mit vier logischen Einheiten
- Auffällig: Komplett fehlende Emoji-Nutzung
- Gut gegliederte Absätze mit klaren Übergängen
Inhaltliche Umsetzung
- Content-Typ: Primär How-To/Tutorial mit Thought Leadership-Elementen
- Einstieg mit doppelter Problem-Frage
- Interessante, aber nicht ganz korrekte Verbindung von GDPR und AI Act
- Starke Betonung der Unternehmensexpertise
- Solide Integration der technischen und sprachlichen Kompetenz
Besondere Stärken
- Klarer, professioneller Schreibstil
- Logischer Aufbau der Argumentation
- Gute Verknüpfung von Problem und Lösung
- Starke B2B-Orientierung
Auffällige Schwächen
- Komplettes Fehlen von Emojis (Prompt-Vorgabe nicht erfüllt)
- Keine Hashtags am Ende (Prompt-Vorgabe nicht erfüllt)
- Etwas zu formeller Ton für LinkedIn
- Marketing-lastiger als die anderen LLMs
Besonderheiten
- Erwähnung von GDPR neben AI Act zeigt interessante, wenn auch nicht ganz präzise Kontextualisierung
- Stärkere Fokussierung auf das Unternehmen als auf die persönliche Expertise
- Sehr formeller, traditioneller B2B-Marketing-Stil
Fazit: Das Modell hat einen inhaltlich soliden, aber formal unvollständigen Post erstellt. Es fehlen wesentliche von Prompt geforderte Elemente (Emojis, Hashtags), und der Ton ist etwas zu formell für LinkedIn. Die inhaltliche Qualität ist gut, aber die Umsetzung entspricht eher einem traditionellen Marketing-Text als einem modernen LinkedIn-Post.
Ein interessanter Aspekt ist, dass dieses Modell den persönlichsten Ansatz vermieden und stattdessen einen stärker unternehmensorientierten Ton gewählt hat – im Gegensatz zu den anderen Modellen, die meine persönliche Expertise stärker in den Vordergrund gestellt haben.
Vergleichende Analyse der 8 LLM-generierten LinkedIn-Posts
Formale Umsetzung der Prompt-Anforderungen
Länge und Struktur
- Optimale Länge: GPT-4, Claude 3.5, Perplexity
- Etwas zu kurz: Mistral-nemo, Gemini
- Beste Strukturierung: GPT-4 und Claude 3.5
- Schwächste Strukturierung: Perplexity (Formatierungsprobleme)
- Zusatzleistung: Llama 3.2 mit Erklärung der eigenen Arbeit
Emoji-Nutzung
- Vorbildlich (3-5 Emojis): Mistral-nemo, Llama 3.2
- Minimal (1-2 Emojis): Claude 3.5, Perplexity, Mistral Le Chat
- Keine Emojis: Tibellium/Towerinstruct, Gemini
- Kreativste Platzierung: Mistral Le Chat (symmetrische Rahmung)
Inhaltliche Qualität
Expertise-Integration
- Herausragend: Claude 3.5 (Fokus auf Dokumentation)
- Sehr gut: GPT-4 (Balance zwischen Technik und Marketing)
- Authentisch: Mistral Le Chat (deutsche Titel)
- Faktenstark: Gemini (regulatorischer Fokus)
- Zu generisch: Tibellium/Towerinstruct
Fachliche Tiefe
- Technische Dokumentation: Claude 3.5
- Regulatorische Aspekte: Gemini, GPT-4
- Praxisrelevanz: Mistral Le Chat, Llama 3.2
- Marktperspektive: Perplexity
Zielgruppenansprache
Tonalität:
- Professionell-dynamisch: GPT-4
- Expertenfokussiert: Claude 3.5
- Dialog-orientiert: Mistral-nemo
- Sachlich-informativ: Gemini
- Zu formell: Tibellium/Towerinstruct
Hauptschwächen
Nach Modellen:
- GPT-4: Kaum Schwächen, könnte emotionaler sein
- Claude 3.5: Sparsame Emoji-Nutzung
- Mistral Le Chat: Etwas zu vorsichtiger Ton
- Gemini 1.5: Fehlende Emojis, zu kurz
- Llama 3.2: Leicht überladen mit Formatierungen
- Mistral-Nemo: Formatierungsprobleme
- Perplexity: Technische Darstellungsmängel
- Tibellium/TowerInstruct: Prompt-Anforderungen teilweise ignoriert
Fazit
Die Analyse zeigt deutliche Qualitätsunterschiede zwischen den Modellen:
Top-Performer:
- ChatGPT-4o und Claude Sonnet 3.5 liefern professionellste Gesamtpakete
- Mistral Le Chat überrascht mit authentischer Expertenpositionierung
- Gemini 1.5 überzeugt durch regulatorische Expertise
Mittelfeld:
- Llama 3.2 zeigt beeindruckende Leistung für lokales Modell
- Mistral-nemo punktet mit Dialogstil
Verbesserungsbedarf:
- Perplexity: Technische Optimierung nötig
- Tibellium/Towerinstruct: Grundlegende Prompt-Befolgung verbessern
Diese Analyse zeigt, dass auch kleinere und lokale Modelle durchaus qualitativ hochwertige Ergebnisse liefern können, während die großen Cloud-Dienste durch Konsistenz und Professionalität überzeugen.
Unique Selling Points
Besondere Stärken
- GPT-4
- Perfekte Balance aller Elemente
- Professioneller Marketing-Stil
- Überzeugende Argumentationsstruktur
- Claude 3.5
- Einzigartiger Dokumentationsfokus
- Tiefgehendes Fachverständnis
- Strategische B2B-Positionierung
- Mistral Le Chat
- Integration deutscher Fachbegriffe
- Authentische Expertenpositionierung
- Zukunftsorientierte Vision
- Gemini 1.5
- Klare regulatorische Perspektive
- GDPR-Integration
- Strukturierte Kernpunkte
- Llama 3.2
- Überraschend professionell
- Gute Emoji-Integration
- Selbstreflexive Zusatzleistung
- Mistral-nemo
- Dynamischer Dialogstil
- Gute Emoji-Nutzung
- Persönliche Ansprache
- Perplexity
- Starke Faktenintegration
- Konkrete Zahlen
- Klare Botschaften
- Tibellium/Towerinstruct
- Solide B2B-Orientierung
- Klare Strukturierung
- Fokus auf Unternehmenswerte
Häufige Fragen
Ja, aber es ist ratsam, für jede Sprache einen eigenen, spezifisch angepassten Prompt zu entwickeln, der kulturelle und sprachliche Besonderheiten berücksichtigt, statt Posts einfach zu übersetzen.
Der Zeitpunkt der Generierung hat keinen Einfluss auf die Qualität. Wichtiger ist die zeitliche Planung der Veröffentlichung, die sich an der Zielgruppen-Aktivität orientieren sollte.
Ja, dies kann sogar vorteilhaft sein. Beispielsweise könnte ein Modell besser für technische Inhalte geeignet sein, während ein anderes überzeugender bei Thought Leadership-Beiträgen ist.
Es empfiehlt sich, einen CI-Checker mit Keywords, Tone-of-Voice-Vorgaben und No-Gos zu erstellen und jeden generierten Post damit abzugleichen. Dies sollte als fester Bestandteil des Review-Prozesses etabliert werden.
Die reine Generierungszeit liegt bei allen getesteten Modellen unter einer Minute. Die Hauptarbeit liegt in der Prompt-Erstellung und der anschließenden Überprüfung/Anpassung des generierten Inhalts, was etwa 10-15 Minuten in Anspruch nimmt.
Ähnliche Beiträge

AI-Consultant-Kompetenz: Mehrwert für Mittelstand und Übersetzungsbranche
Dieser Artikel zeigt, wie KI die Übersetzungs- und Marketingprozesse in der Fertigungsindustrie optimiert und effizienter gestaltet.

Die Evolution der Künstlichen Intelligenz
Entwicklung von KI bis hin zu LLMs: So revolutionieren Large-Language-Models die technische Übersetzung mit firmenspezifischen Terminologien

LLMs (Large Language Models) und Datensicherheit
Bei der KI Übersetzung mit memoQ AGT wird ein Large Language Model (LLM) genutzt, um Übersetzungsvorschläge zu generieren und so Datensicherheit zu gewährleisten.

Pflichten und Herausforderungen des EU AI Acts für Unternehmen und Berater
Erfahren Sie, welche Pflichten der EU AI Act für Unternehmen und Berater bringt und wie Sie sich auf die schrittweise Einführung der weltweit ersten KI-Verordnung vorbereiten können

Optimierung von Large Language Models
Optimierung von LLMs: Methoden wie Prompt-Design, RAG und Fine-Tuning erhöhen die Präzision und Anpassungsfähigkeit der Modellantworten. Erfahren Sie, welche Strategie sich für verschiedene Anwendungen eignet.